A volumetria determina a arquitetura
Uma boa arquitetura pode inviabilizar um bom projeto na nuvem. Pode parecer um paradoxo, mas quando uma arquitetura não considera a volumetria e os custos associados dos serviços, os exemplos abundam. Uma das causas deste fenômeno é continuar pensando da mesma forma na hora de resolver problemas, novos ou não.
Um exemplo prático
Imagine um serviço de envio de emails em massa, enviando cerca de 7 Milhões de emails/dia. A infra estrutura na nuvem é baseada em servidores EC2, com auto-scaling tanto para as máquinas de processamento dos emails quanto o cluster responsável pelo processamento do retorno e emissão de relatórios gerenciais.
O processo de envio tem início com o recebimento do arquivo via upload com a lista de emails a serem enviados (arquivo csv). O arquivo deve lido e os dados inseridos no banco de dados ao mesmo tempo. Este processo é custoso para o banco de dados, ocorrendo degradação à medida em que a base cresce.
A arquitetura da solução é demonstrada abaixo:
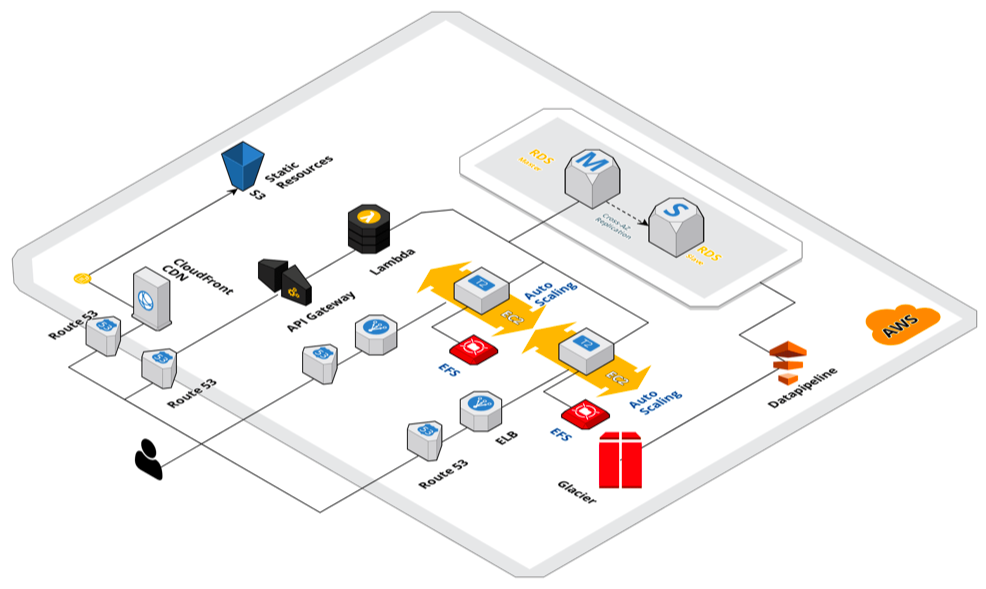
O problema mais simples de resolver é a eliminação completa do cluster usado para gerenciar os uploads. Isto requer uma mudança na aplicação que consiste na chamada de um serviço Lambda, um bucket no S3 e um evento no CloudWatch para processar o arquivo uma vez recebido.
A função Lambda abaixo demonstra como fazer a assinatura do arquivo. Note que estamos assinando o path com o nome do arquivo, não o arquivo em si. O arquivo será submetido pela aplicação diretamente para o S3 usando a assinatura devolvida pela função Lambda, sem custos de envio.
/**
* Gera a assinatura de um arquivo para upload para o s3
*/
var crypto = require('crypto'),
awsKey = "ACCESS KEY",
secret = "ACCESS KEY SECRET",
maxSizeFile = 100000000, // 100MB,
minSizeFile = 1; // 1MB,
exports.handler = (event, context, callback) => {
var body = event["body-json"],
expiration = new Date(new Date()
.getTime() + 1000 * 60 * 5)
.toISOString(),
bucket = `myfiles-media-bucket-${event.context.stage.toLowerCase()}`;
if (!body.size || !body.type) {
return callback(400, "[BadRequest] Missing Parameters");
}
if (body.size > maxSizeFile) {
return callback(400, "[BadRequest] Very large file");
}
var key = `media/${body.prefix}/temp/` + (new Date())
.getTime() + '.' + body.type;
var acl = 'public-read';
var conditionsObjects = {
bucket,
key,
acl
}
if (body.params) {
for (let key in body.params) {
body.params[key] = encodeURI(body.params[key]);
conditionsObjects[key] = body.params[key];
}
}
var conditionsArray = [
["starts-with", "$Content-Type", ""],
["content-length-range", minSizeFile, maxSizeFile]
];
for (let key in conditionsObjects) {
conditionsArray.push({
[key]: conditionsObjects[key]
})
}
var policy = {
"expiration": expiration,
"conditions": conditionsArray
},
policyB64 = new Buffer(JSON.stringify(policy), 'utf8').toString('base64'),
signature = crypto.createHmac('sha1', secret)
.update(policyB64)
.digest('base64');
callback(null, {
bucket,
awsKey,
"policy": policyB64,
signature,
key,
acl,
"params": body.params
});
}O custo total do upload passa agora para US$ 0.00001667. Lembrando que o upload em si não possui custo, todo custo do processo é a chamada da função para assinar a URL, que ainda possui a vantagem de suportar múltiplos processos e alta concorrência de usuários. Com isto eliminamos a necessidade de servidores. Do lado da aplicação é necessário mudar a forma como o arquivo é submetido. O processo é descrito abaixo:
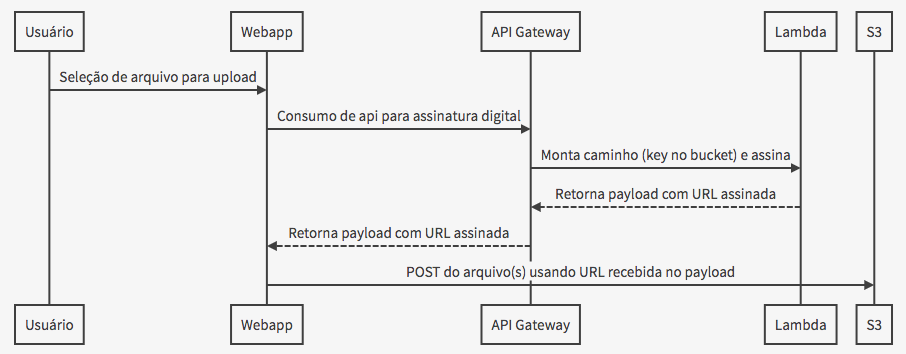
O processo pode ser resumido como consumir uma API e fazer um post com a URL devolvida.
Processando o upload
A segunda parte é um pouco mais complexa, o que fazer para ter capacidade de processamento pesado, mas sem ter servidores? Primeiro vamos revisar algumas tecnologias disponibilizadas pela AWS, começando pelo S3.
Eventos no S3
Uma vez recebido o arquivo é necessário processar seu conteúdo e iniciar o envio dos emails. Isto requer que o processo de processamento seja iniciado pelo S3 tão logo o arquivo tenha sido recebido. Isto é obtido pelo recurso do S3 chamado "Events":
Nas propriedades do bucket para onde será feito o upload temos a definição da função Lambda que será executada quando um arquivo for submetido:
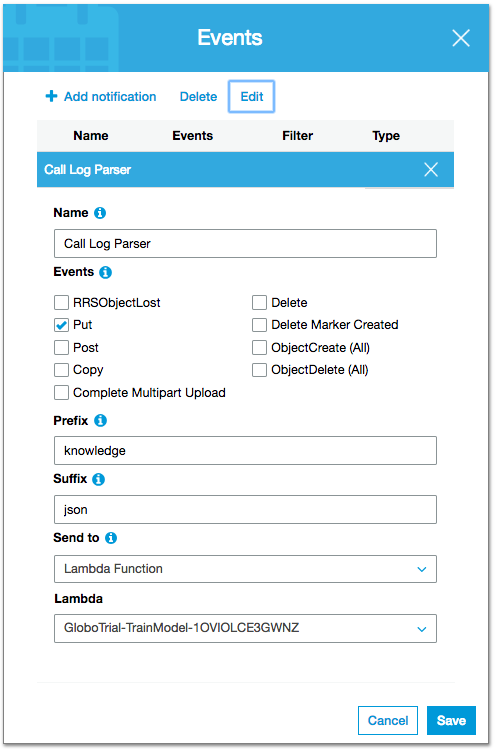
É possível disparar o evento de forma condicional, indicando que o mesmo deve iniciar apenas para certos arquivos ou arquivos iniciados com certos padrões ou que tenham certas extensões. A função Lambda não processará diretamente o arquivo em questão, mas será usado para chamar um processo mais robusto que será capaz de realizar a tarefa em questão.
Lambda e ECS
Lambda é conveniente para muitas questões, mas quando trata-se de processamento que pode levar dezenas de minutos ou mesmo horas, encontramos limitações como o tempo máximo de execução (300 segundos) ou a quantidade de memória RAM que pode ser definida para uma função (3GB). O que precisamos é de uma função simples, que inicie um processo capaz de lidar com a demanda de processamento. Para o processamento intenso utilizaremos o ECS - Fargate com uma pequena ajuda do SQS (Simple Queue Service). Zero servidores, todo o poder computacional necessário sob demanda.
A arquitetura proposta tem o seguinte fluxo:
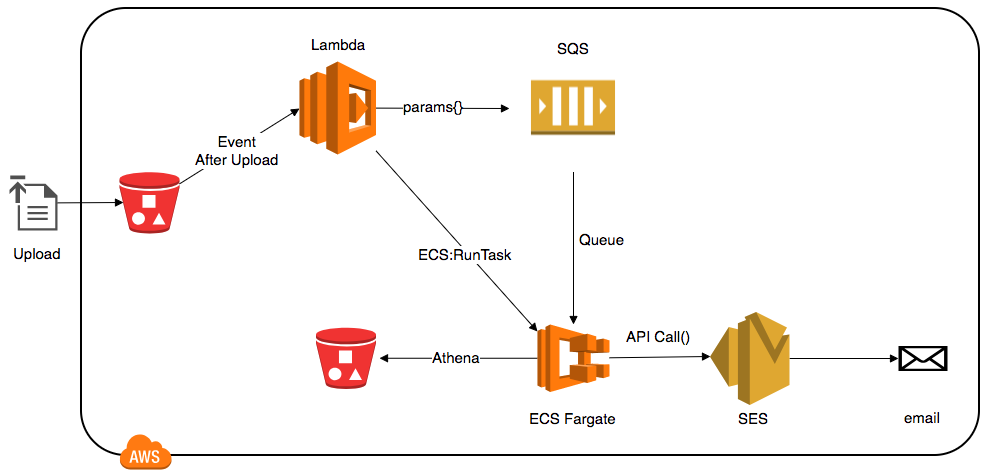
Arquitetura proposta para processamento dos arquivos e envio dos emails, substituindo servidores EC2 com Auto-Scale
No exemplo acima embora existam dois buckets, trata-se do mesmo, mas usado em dois momentos distintos.
Esta arquitetura possui diversas vantagens, incluindo a escalabilidade e o baixo custo. Outras vantagens incluem baixo custo operacional, escalabilidade, custos sob demanda (pague apenas pelo o quê você usar)
Função Lambda
A função abaixo coloca numa fila do SQS uma mensagem com os parâmetros a serem processados pelo nosso script que rodará no ECS. A função também cria a instância do ECS e finaliza logo após.
var async = require('async');
var aws = require('aws-sdk');
var sqs = new aws.SQS({apiVersion: '2012-11-05', region: 'us-east-1'});
var ecs = new aws.ECS({apiVersion: '2014-11-13', region: 'us-east-1'});
exports.handler = function(event, context, callback) {
const stage = event.context.stage;
let eventSQS = {
'bucket': event.Records[0].s3.bucket.name,
'key': event.Records[0].s3.object.key,
'params' : event,
'stage' : stage.toLowerCase()
}
async.waterfall([
/**
* Armazenando os parametros no SQS
*/
function (next) {
var params = {
MessageGroupId: MY_QUEUE_GROUP,
MessageBody: JSON.stringify(eventSQS),
QueueUrl: YOUR_QUEUE_URL
};
sqs.sendMessage(params, function (err, data) {
if (err) { console.warn('Error while sending message: ' + err); }
else { console.info('Message sent, ID: ' + data.MessageId); }
next(err);
});
},
/**
* Ativando a ECS
*/
function (next) {
var params = {
cluster: YOUR_CLUSTER,
taskDefinition: YOUR_TASK,
launchType: "FARGATE",
networkConfiguration: {
awsvpcConfiguration: {
assignPublicIp: "ENABLED",
securityGroups: [YOUR_SECURITY_GROUP],
subnets: [YOUR_SUBNET1, YOUR_SUBNET2]
}
},
count: 1
};
ecs.runTask (params, function (err, data) {
if (err) {console.warn ('error:', "Erro ao iniciar a tarefa:" + err); }
else {console.info ('Task' + YOUR_TASK + 'started:' + JSON.stringify (data.tasks))}
next(err);
});
}
], function (err) {
if (err) {
console.log(err);
callback(err);
}
else {
callback(null, 'Success');
}
}
);
};Script no ECS que processará o envio
O shell script abaixo (Posix compatible) usa o AWS CLI para ler a fila do SQS, baixar e executar do S3 o script NodeJS de processamento de emails. Usando um modelo semelhante é possível manter a imagem no ECS na forma mais simples
#!/bin/sh
die()
{
BASE=$(basename -- "$0")
echo "$BASE: error: $@" >&2
exit 1
}
set_aws_profile_param()
{
## Which AWS profile to use from configuration file (~/.aws/config) ?
## If empty, uses the [Default].
AWS_PROFILE_PARAM=""
test -n "$AWS_PROFILE" && AWS_PROFILE_PARAM="--profile $AWS_PROFILE"
}
get_queue_url()
{
test -n "$1" || die "missing QUEUE_NAME param to get_queue_url()"
## Get Qeueu URL from AWS (as JSON reposonse)
__tmp=$(aws $AWS_PROFILE_PARAM \
--output=json \
sqs get-queue-url --queue-name "$1") \
|| die "failed to get queue URL for '$1'"
## return queue URL as a string)
echo "$__tmp" | jq -r '.QueueUrl' \
|| die "failed to extract queue URL from JSON for '$1'"
}
usage()
{
BASE=$(basename -- "$0")
echo "SQS Example
Usage:
$BASE
Will get a job from the SQS queue,
printing the filename, value and receipt handle.
"
exit 1
}
# A fila deve ser do tipo FIFO para que a solução processe corretamente as solicitações em ordem cronológica
QUEUE_NAME=${QUEUE_NAME:-SUA_FILA_NO_SQS.fifo}
set_aws_profile_param
QUEUE_URL=$(get_queue_url "$QUEUE_NAME") || exit 1
JSON=$(aws $AWS_PROFILE_PARAM \
--output=json \
sqs receive-message \
--queue-url "$QUEUE_URL") \
|| die "failed to receive-message from SQS queue '$QUEUE_NAME'"
[ -z "$JSON" ] && continue
# Number of messages
NUM=$(echo "$JSON" | jq '.Messages[] | length') \
|| die "failed to get number of messages from JSON: $JSON"
##test -n $NUM && die "no pending messages"
## Quit if no messages
##test "$NUM" -eq 0 && die "no pending messages"
## We expect exactly one message
echo "NUM: $NUM";
test "$NUM" -ne 0 \
## || die "got too many messages from SQS: $JSON"
## Extract Receipt Handle from JSON
RECEIPT=$(echo "$JSON" | jq -r '.Messages[] | .ReceiptHandle') \
|| die "failed to extract ReceiptHandle from JSON: $JSON"
## The Extract the body of the message - which is itself a JSON file.
BODY=$(echo "$JSON" | jq -r '.Messages[] | .Body') \
|| die "failed to extract message body from JSON: $JSON"
FILENAME=$(echo "$BODY" | jq -r '.filename') \
|| die "failed to extract job's filename from JSON: $JSON"
VALUE=$(echo "$BODY" | jq -r '.value') \
|| die "failed to extract job's value from JSON: $JSON"
echo "FILENAME: $FILENAME
VALUE: $VALUE
BODY: $BODY
RECEIPT-HANDLE: $RECEIPT"
## S3
BUCKET=$(echo "$BODY" | jq -r '.bucket') \
|| die "failed to extract bucket from JSON: $JSON"
KEY=$(echo "$BODY" | jq -r '.key') \
|| die "failed to extract key from JSON: $JSON"
echo "Copying ${KEY} from S3 bucket ${BUCKET}..."
mkdir scripts
cd scripts
aws s3 cp s3://NOME-DO-BUCKET-COM-SCRIPTS/${KEY} . --region us-east-1 --recursive
##Resolvendo dependências do script NodeJS
npm install
PARAMS=$(echo "$BODY" | jq -r '.params') \
|| die "failed to extract key from JSON: $JSON"
node index.js params="$PARAMS"
cd ..
rm -fr scripts
##Após processamento, remover item da fila
aws sqs delete-message \
--queue-url ${QUEUE_URL} \
--region us-east-1 \
--receipt-handle "${RECEIPT}"
echo "Removido da fila";Queries com Athena
Agora que temos um modelo baseado no docker para a execução do serviço, precisamos diminuir a dependência do banco de dados para o envio. O AWS Athena é capaz de executar queries (SQL) contra conteúdo disponibilizado nos buckets (JSON, CSV etc), incluindo conteúdo compactado (zip). Isto é uma enorme facilidade que dispensa o uso de banco de dados relacional em muitas situações. No nosso caso serve perfeitamente e é o que iremos utilizar no script Node que será executado pelo container e que é disparado pelo shell script acima.
A tabela será criada a partir de arquivo CSV com a seguinte estrutura:
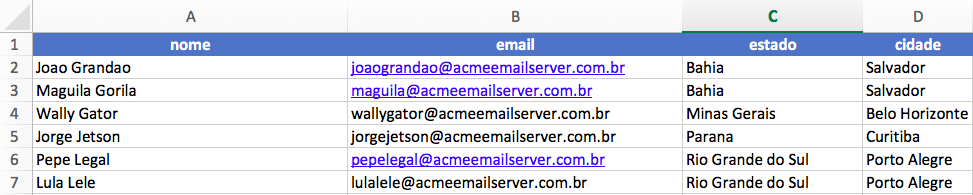
CREATE EXTERNAL TABLE IF NOT EXISTS AthenaUsersDatabase.athena_users_table (
`nome` string,
`email` string,
`estado` string,
`cidade` string
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES (
'serialization.format' = ',',
'field.delim' = ','
) LOCATION 's3://marketing-datalake/usuarios/'
TBLPROPERTIES ('has_encrypted_data'='false');Uma vez que o arquivo seja submetido para o S3, o seu conteúdo poderá ser recuperado através de uma query SQL comum:
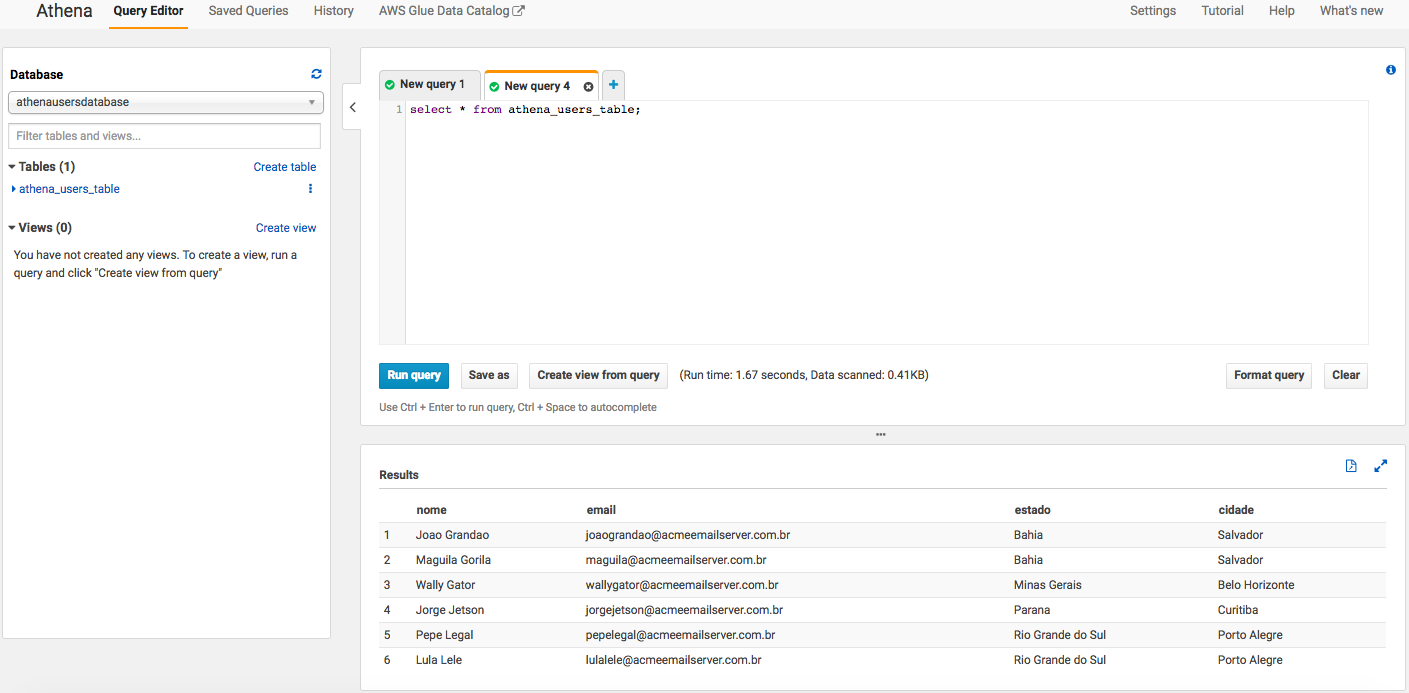
Agora que temos nossa estrutura pronta, o script que rodará no ECS pode acessar os dados submetidos pelo upload. Um exemplo simples de query pode ser visto a seguir:
var clientConfig = {
bucketUri: 's3://marketing-datalake/usuarios'
}
var awsConfig = {
region: 'us-east-1',
}
var athena = require("athena-client")
var client = athena.createClient(clientConfig, awsConfig)
client.execute('SELECT * FROM athenausersdatabase.athena_users_table;;').toPromise()
.then(function(data) {
// aqui entra o código para envio do email pelo SES
console.log(data)
})
.catch(function(err) {
console.error(err)
})Comparando custos
Uma comparação direta dos custos de banco de dados permite avaliar a diferença de custos das diferentes abordagens.
Abordagem usando banco de dados relacional | Abordagem usando S3 e Athena |
 | 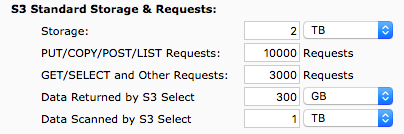 |
 |  |
Comparativo
Considerações finais
O objetivo deste artigo não é eliminar o banco de dados da arquitetura, mas diminuir o seu custo, removendo a dependência dele para a execução de tarefas que podem ser desempenhadas de forma mais eficiente em termos de escalabilidade e custos através de serviços como o S3/Athena ou mesmo o ElastiCache (Redis). Existem limites práticos no caso do Athena como a capacidade de executar 20 queries concorrentes (embora este limite possa ser aumentado requisitando uma mudança ao suporte da AWS). Em cada caso considerar em primeiro lugar a volumetria é o primeiro passo na direção certa para manter o orçamento sob controle.


